Scheduling
The scheduler is responsible for determining the order in which tasks are executed (“task” can have different meanings and can be used interchangeably with “thread” in these notes). A simplified view of task states is:
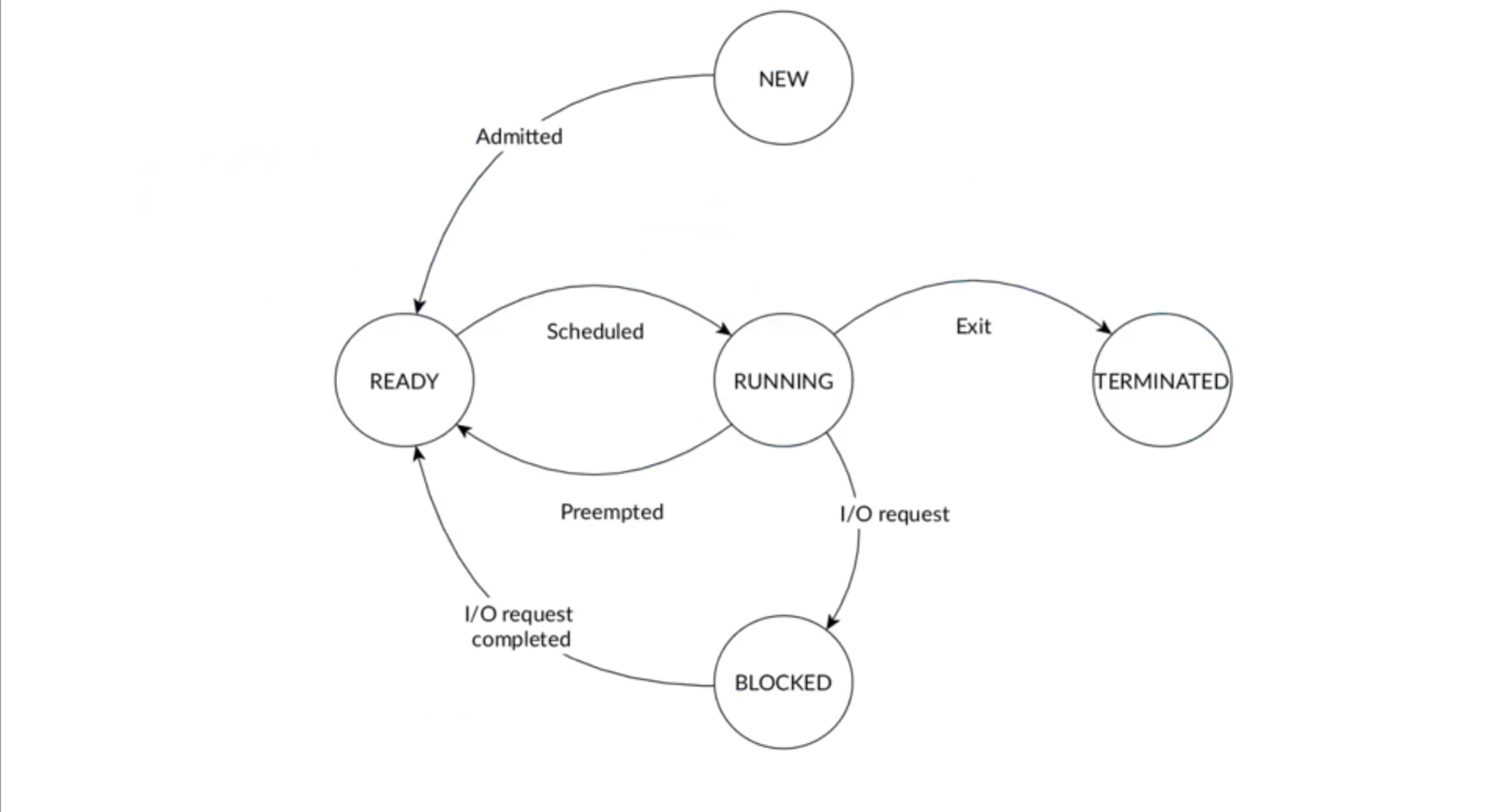
Actually the reality in Linux is much more complex and there are a lot of possible things that can happen to the process like errors, special states etc.
When studying the scheduling of processes we have a couple of metrics to consider:
a_i: Arrival time, which is when a task becomes ready for scheduling.s_i: Start time, which indicates when a task begins execution.R_i: Response time, which is the time from arrival to first quantum slice ends.W_i: Wait time, which is the total time spent waiting in the queue by a task.f_i: Finishing time, which denotes when a task completes its execution.C_i: Computation time or burst time, which represents the duration required for the processor to execute the task without any interruptions.Z_i: Turnaround time, which is the overall time taken from when a task becomes ready until it completes its execution. It is given by the equationZ_i = f_i - a_i. Note thatZ_iis not necessarily equal toW_i + C_ibecause interruptions could occur.
Based on the nature of the operations performed by a task, we categorize processes as either CPU-bound or I/O bound:
- CPU-bound processes primarily spend their time executing computations. In this case,
Z_iis approximately equal toW_i + C_i. - I/O bound processes spend most of their time waiting for I/O operations. Here,
Z_iis significantly higher thanW_i + C_i.
Scheduling in an OS is a critical task involving the decision of which process to run next. The scheduling policy should aim to balance several factors:
- Fairness:
- Ensure the scheduling is fair and that no process is starving.
- Throughput:
- Aim for maximum process completion rate.
- Efficiency:
- Minimize the resources used by the scheduler itself.
- Optimize CPU usage reducing context switching overhead.
- Priority:
- Reflect the relative importance or urgency of processes.
- Deadlines:
- Meet time constraints for time-sensitive operations like real-time tasks like multimedia playback or similar.
Note that OS scheduling strategies are balancing conflicting goals like deadlines and fairness. For this reason we must make a distinction domain-Specific Scheduling:
- General-Purpose OSes GPOS: Balance throughput, fairness, user response; utilize time-sharing, dynamic priorities.
- Real-Time Operating Systems RTOS: Prioritize deadlines, predictability; apply RMS, EDF algorithms.
Additionally, user and kernel mode processes may have different priorities. But also I/O-Bound and CPU-Bound processes need a distinction for resource efficiency. Multicore/Multiprocessor environments add scheduling complexities and adaptive Scheduling adjusts priorities and nakes decisions based on system load and process activity.
Scheduling algorithms
The algorithm used by the scheduler to determine the order is called the scheduling policy. Computing an optimal schedule and resource allocation is an NP-complete problem. To increase the complexity we have to keep in mind that these objectives often conflict with each other:
- maximize processor utilization
- maximize throughput: number of tasks completing per time unit
- minimize waiting time: time spent ready in the wait queue
- ensure fairness
- minimize scheduling overhead
- minimize turnaround time
- and many more: energy, power, temps, …
Also there is the problem of starvation. Schedulers can be categorized into different types based on their characteristics.
- Preemptive vs Non-preemptive:
- Preemptive is the ability to interrupt tasks and allocate the CPU to another task ensuring responsiveness.
- Non-preemptive schedulers minimizes overhead but can impact responsiveness.
- Static vs Dynamic:
- Static schedulers make decisions based on fixed parameters and are not be realistic in general-purpose systems.
- Dynamic schedulers make decisions based on runtime parameters.
- Offline vs Online:
- Offline schedulers are executed once before task activation, and the resulting inflexible schedule remains unchanged.
- Online schedulers are executed during task execution at runtime, allowing for the addition of new tasks.
- Optimal vs Heuristic:
- Optimal schedulers typically come with higher overhead and complexity.
- Heuristic schedulers are not optimal but are usually more efficient in terms of overhead.
What are the menu offerings?
| Name | Target (Goal) | Preemptive |
|---|---|---|
FIFO | turnaround | No |
SJF | waiting time | No |
HRRN | waiting time | No |
SRTF | waiting time | Yes |
Round-robin | response time | Yes |
CFS | CPU fair share | Yes |
First-In-First-Out (FIFO)
Simplest scheduling algorithm possible, also known as First Come First Served (FCFS). FIFO blueprint:
- Tasks are scheduled in the order of arrival
- Non-preemptive
- Very simple
- Not good for responsiveness
- Long tasks may monopolize the processor
- Short tasks are penalized
Shortest Job First (SJF)
Shortest Job First (SJF) scheduler aims to minimize the waiting time of processes. Also known as Shortest Job Next (SJN). SJF blueprint:
- It selects the process with the shortest computation time
C_iand executes it first. - Non-preemptive
- Starvation for long tasksthe main disadvantage
- How the fuck you know in advance?
This makes SJF less ideal in environments with a high variance in task length or where fairness among tasks is a crucial requirement.
A possible alternative that mitigates starvation is the Highest Response Ratio Next (HRRN) scheduler.
Shortest Remaining Time First (SRTF)
SRTF uses the remaining execution time instead of the total to decide which task to run. SRTF blueprint:
- Improve responsiveness for all tasks compared to SJF
- Starvation for long tasks
- We need to know in advance as SJF
Highest Response Ratio Next (HRRN)
HRRN selects the task with the highest Response Ratio:
HRRN blueprint:
- Non-preemptive
- Prevent starvation
- We need to know in advance
Round Robin (RR)
RR is very popular and very simple and also very adopted in modern OS. Tasks are scheduled for a given time slice and then preempted to give time to other tasks. RR blueprint:
- Preemptive: when the time quantum expires, the task is moved back to the ready queue.
- Computable maximum waiting time:
- No need to know in advance
- Good to achieve the fairness and responsiveness goals
- No starvation is possible
- Turnaround time worse than SJF
Tasks in a ready queue are added based on FIFO policy. If an executing task gets preempted while a new task has been added in the ready queue, the new task has precedence in the queue over the preempted task.
In Linux, the default time quantum for the Round Robin (RR) scheduler is stored in /proc/sys/kernel/sched_rr_timeslice_ms, with a default value of 100ms.
The total overhead depends on the number of preemptions, and so it can be reduced by increasing the quantum . Obviously, the disadvantage of choosing a larger quantum value is the increasing of the average turnaround and waiting time.
CFS (Completely Fair Scheduler)
CFS attempts to balance a process’s virtual runtime with a simple rule: CFS picks the process with the smallest virtual runtime (vruntime), which represents the time a task should run on the CPU.
CFS uses a red-black tree to find the task with the smallest vruntime efficiently.
If here’re no runnable processes, CFS schedules the idle task.
In Linux, the transition from the scheduler to the CFS marked a significant evolution in process scheduling, emphasizing fairness and dynamic adaptability.
The scheduler (known for its constant time complexity) offered quick scheduling decisions but struggled with fair CPU time distribution, especially for long-running tasks. This was due to its reliance on fixed timeslices, which could lead to task starvation.
CFS dynamically adjusts time slices in proportion to the task’s priority. All it’s based on the ‘nice’ value
The nice value it’s then used in this exponential formula:
(current values = 1024, The exponential formula is then used for compute the weight derived from the task’s nice value (), influencing its share of CPU time:
The targeted latency reflects the desired period within which all runnable tasks receive CPU time, while the minimum granularity () ensures a lower bound on the timeslice, preventing excessive preemption.
Then for each process , its time-slice is computed as:
Cgroups
CFS alone is not enough to guarantee optimal CPU usage, especially when there are multiple threads from different user: for example, if user A with 2 threads and user B with threads, user A will only be given 2% of the CPU time, which is not ideal. Each user should be given an equal share of the CPU, which is then divided among their threads.
Cgroups is a mechanism for guarantee fairness and optimal cpu usage when there are multiple users: it allocates CPU usage based on groups rather than individual threads.
Load balancing in CFS
Load balancing in CFS is done using a work stealing approach, where each idle core balances its workload by attempting to steal threads from the busiest core (also known as the designated core).
Scheduling classes
A scheduling class is an API (set of functions) that include an unique scheduling algorithm/policy-specific code. This allows developers to implement thread schedulers without reimplementing generic code and also helps minimizing the number of bugs. Which are these scheduling class in linux?
SCHED_DEADLINESCHED_FIFOSCHED_RRSCHED_OTHERSCHED_BATCHSCHED_IDLE
Or in more detailed way:
| Scheduling Class | Description | Scheduling Algorithm | Type of Target Processes |
|---|---|---|---|
| SCHED_DEADLINE | Deadline-based | (EDF) Earliest Deadline First | Real-time |
| SCHED_FIFO | Soft real‑time processes, continue to run until higher priority task is ready. | First-In-First-Out | Real-time |
| SCHED_RR | Share with timeslice | Round-Robin | Real-time |
| SCHED_OTHER / SCHED_NORMAL | Variable-priority | Completely Fair Scheduler (CFS) | Not real-time |
| SCHED_BATCH | Low-priority | CFS with idle task prioritization | Not real-time |
Real-time processes ; they belong to scheduling class SCHED_FIFO or SCHED_RR or SCHED_DEADLINE.
SCHED_NORMAL and SCHED_BATCH are implemented through CFS. The difference is that SCHED_BATCH has a longer timeslice (1.5s) thereby allowing tasks to run longer and make better use of caches but at the cost of interactivity. This is well suited for batch jobs.
Non real-time processes which depend on a nice value : .
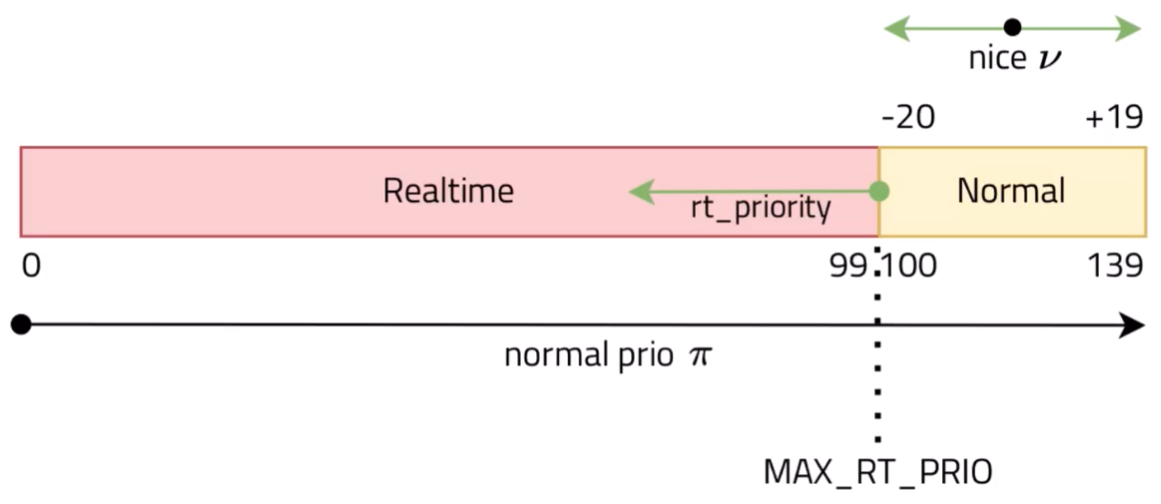
The nice value is only applicable to non-real-time processes, specifically those in the SCHED_OTHER (also known as SCHED_NORMAL) scheduling class. The nice value ranges from -20 (highest priority within this class) to +19 (lowest priority within this class). These nice values are used by the Completely Fair Scheduler (CFS) to adjust the share of CPU time that processes get, with lower nice values giving a process more priority, hence more CPU time.
Regarding process priorities, Linux uses a priority range from 0 to 139, where:
- Priorities 0 to 99 are reserved for real-time priorities (higher value, higher priority), used in scheduling classes like
SCHED_FIFO,SCHED_RR, andSCHED_DEADLINE. - Priorities 100 to 139 are for non-real-time tasks, with the
SCHED_OTHER(orSCHED_NORMAL) andSCHED_BATCHclasses. Within this range, the effect of thenicevalue is evident.
It might seem counterintuitive, but within the Linux kernel’s scheduling system, a lower priority number means a higher priority for getting CPU time. This is particularly true for real-time tasks where a priority of 0 is the highest possible priority. This scheme allows real-time tasks (with priorities 0 to 99) to always preempt non-real-time tasks (with priorities 100 to 139) regardless of their nice values.
So, in summary:
nicevalues are used to adjust priorities within the non-real-time priority range ( to ).- Real-time tasks, which ignore
nicevalues, have priorities in the range of to , where a lower number means higher priority.
Regarding the rest, Linux chooses a simple fixed-priority list to determine this order (deadline real-time fair idle).
Priority is selected depending on the workload type:
- CPU-bound tasks have low priority (high quantum value)
- I/O-bound tasks have high priority (low quantum value)
How to know if a task is CPU-bound or I/O-bound?
- A run-time feedback mechanism: a a new task is always placed in the highest priority queue with the lowest quantum value. If the quantum expires, the task is progressively moved in queues with longer time quantum.
- Or manually set by the user
Multi-Processor Scheduling
In a multi-processor system, the scheduler must decide not only which task to execute but also on which processor to assign. This can be a challenging decision due to various factors such as the occurrence of task synchronization across parallel executions and the difficulty of achieving high utilization of all processors or CPU cores. Additionally, managing correctly cache memory which can significantly enhance overall performance by enabling faster access to frequently used data, reducing the reliance on slower main memory access.
- Load balancing: evenly distributing tasks across different queues to positively impact power consumption, energy efficiency, and system reliability. It’s typically performed via task migration which can be implemented mainly in 2 ways:
- push model: a dedicated task periodically checks the lengths of the queues and moves tasks if balancing is required.
- pull model: each processor notifying an empty queue condition and picking tasks from other queues.
- Hierarchical queues: a hierarchy of schedulers can be implemented to manage task dispatching in a global queue and local ready queues. Improved scalability with maybe more complex.