From perceptron to Feed Forward Neural Networks
The concept of neural networks has been around since the 1950s. Initially, it involved building hardware that could mimic human-like behaviour and perform tasks that only humans were thought to be able to do.
Perceptron
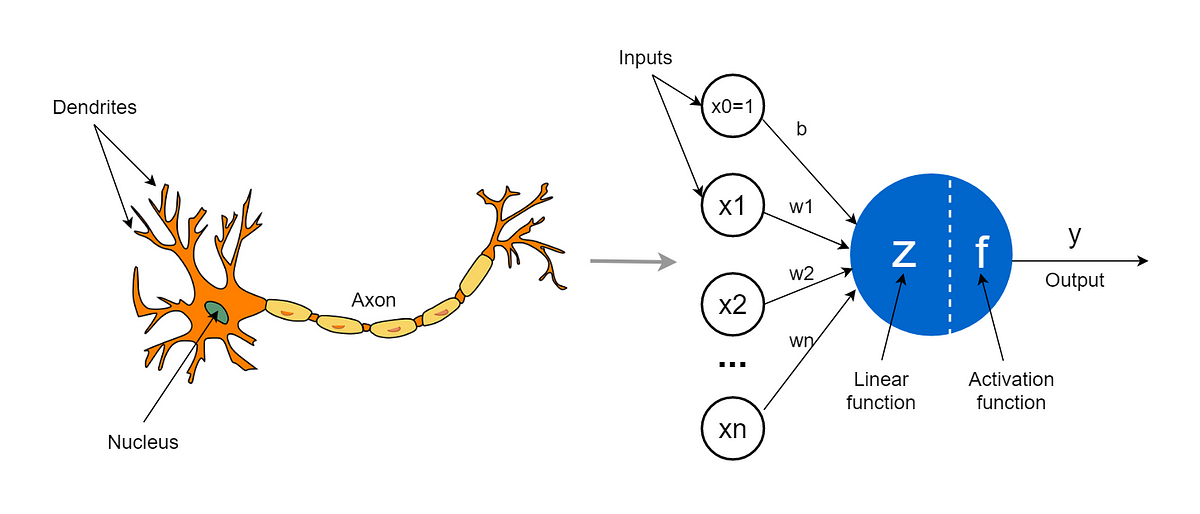
A perceptron can be seen as a mathematical model of the neurons. We want to mimic this non-linear system where there is a sort of threshold: the signals arrive from other neurons, but only if the sum of signals exceeds the threshold the neuron activates.
The basic structure of a perceptron can be seen as:
In this equation, are the input features, are the weights assigned to each input feature, is the bias term, and is the output of the perceptron. The perceptron calculates the dot product of the weights and inputs, adds the bias term, and then applies the activation function (which in this case is a step function). If the result is greater than zero, the output is 1 , and if it is less than or equal to zero, the output is -1 .
It’s a non-linear function of a linear combination: the inputs are combined linearly (sum of weighted inputs plus a bias), and then this result is transformed by a non-linear function (the activation function).
Why this non-linearity is so important?
- Linear models can only represent linear relationships. Non-linear functions in neural networks can approximate a wider range of functions, including intricate and complex relationships in data.
- Non-linear activation functions also allow for the stacking of layers in deep neural networks which would not be possible with linear functions which would collapse into a single linear layer.
- Many real-world phenomena are non-linear, so non-linear representations are necessary to accurately reflect them.
Sometimes the bias is just seen as another parameter .
Feedforward Neural Networks
Feedforward neural networks are typically represented by composing together many different functions. The model is associated with a directed acyclic graph describing how the functions are composed together.
These networks have only information flowing forward in a chain of functions (that’s why are called feed-forward neurons) called layers.
The depth of the model is determined by the number of layers in the chain.
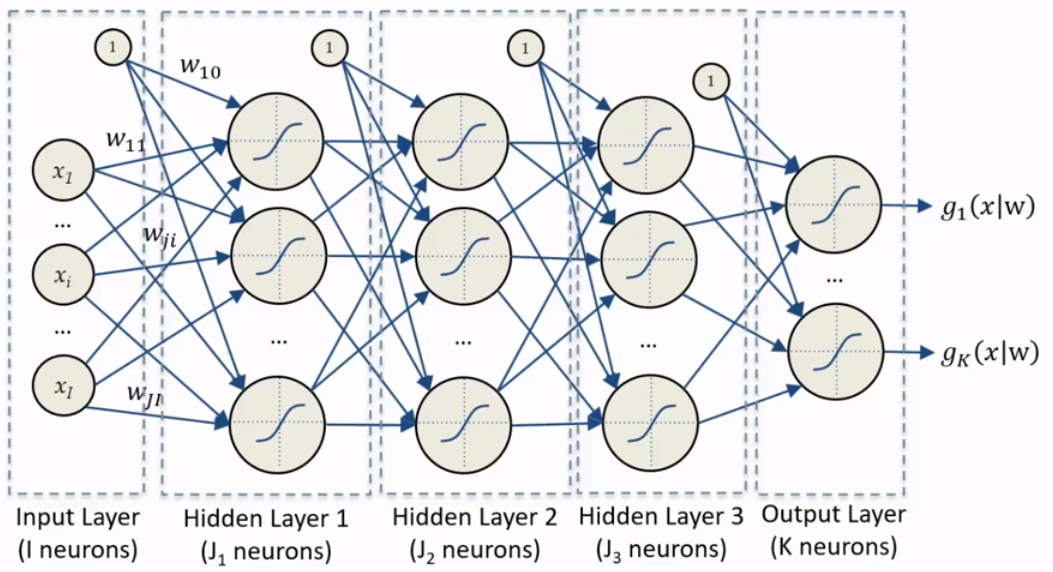
The structure is as it follows:
In a feedforward neural network, the computation of each layer is performed using this equation, where are the input features, is the weight of the connection between the input and the output , is the bias term for the output , and is the output of the layer for the output .
Hebbian learning
“The strength of a synapse increases according to the simultaneous activation of the relative input and the desired target” (Donald Hebb, The Organization of Behaviour, 1949)
Hebbian learning is a rule in neural networks that adjusts the strength of connections between neurons based on their activity. It states that if two neurons are active simultaneously, their connection is strengthened. This is known as “Hebb’s rule” or “Hebbian learning rule”. The weight of the connection between and neurons is calculated using:
Where we have:
- : learning rate
- : the input of neuron at time
- : the desired output of neuron at time
Starting from a random initialization, the weights are updated for each sample individually in an online way. Only update the weights if the sample is not predicted correctly.
Universal approximation theorem (Kurt Hornik, 1991)
“A single hidden layer feedforward neural network with shaped activation functions can approximate any measurable function to any desired degree of accuracy on a compact set” (Kurt Hornik, 1991)
Which basically means that FFNN can represent any function but actually:
- finding the necessary weights may not be possible for a learning algorithm.
- In the worst case scenario, an exponential number of hidden units may be needed.
- The layer may become unreasonably large and fail to learn and generalize effectively.
Starting from a random initialization, the weights are fixed one sample at the time (online) and only if the sample is not correctly predicted. The weight of the connection between and neurons is calculated using:
We are trying to minimize the cost function or loss function of the neural network. The cost function measures how well the neural network is performing on a given set of training examples. By minimizing this cost function, we aim to improve the accuracy and performance of the neural network model. To find the minimum of a generic function, we compute the partial derivatives of the loss function in respect to the parameters and set them to zero