seq2seq
Sequence-to-sequence (seq2seq) learning is used to convert a sequence of input data into a sequence of output data. It’s frequently used in NLP context.
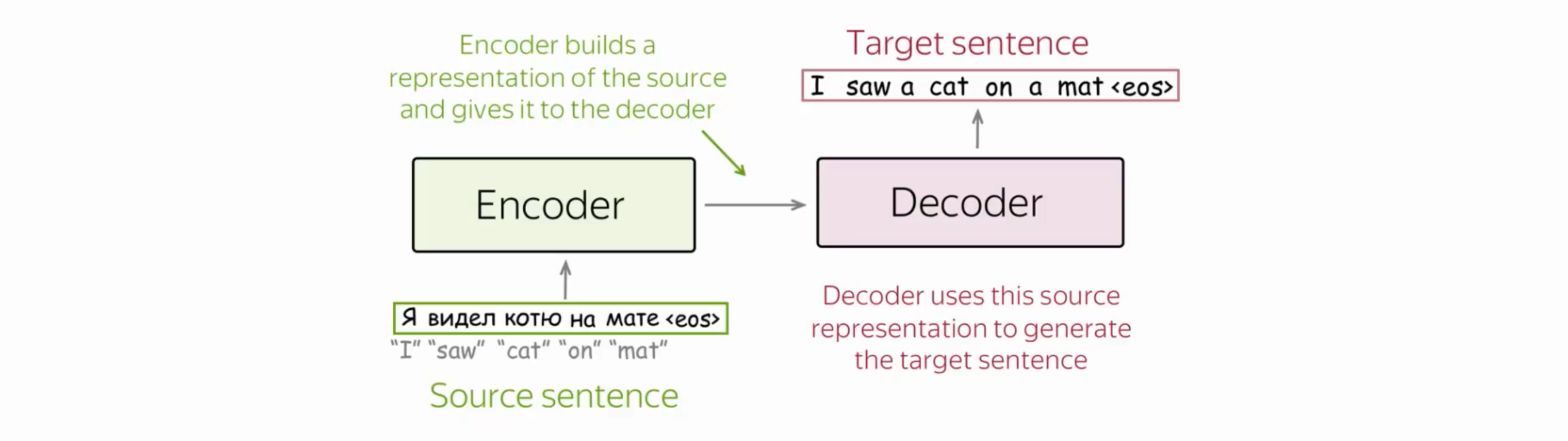
The target sentence is generated in the target language, word by word, until the end-of-sequence token (<EOS>) is produced.
Different tokens are necessary:
<PAD>: During training, examples are fed to the network in batches. The inputs in these batches need to be the same width. This is used to pad shorter inputs to the same width of the batch
<EOS>: Needed for batching on the decoder side. It tells the decoder where a sentence ends, and it allows the decoder to indicate the same thing in its outputs as well.
<UNK>: On real data, it can vastly improve the resource efficiency to ignore words that do not show.
up often enough in your vocabulary by replace those with this character.
<SOS>/<GO>: This is the input to the first time step of the decoder to let the decoder know when to start generating output.
Encoding text is a serious thing: words lives in an high dimensional space but very sparse → curse of dimensionality .
That’s why we used word embedding, which helps simplify the process and improve performance. Word embedding turns a word to a lower‐dimensional numerical vector space.
Different approaches regarding local representations: - N-Grams: A sequence of items from a given text. It focus on capturing the local sequence of words and their context. The goal is predict the probability of a sentence given the previous words, called “context”. Determine in some domain of interest. - Bag-of-words: A representation of text that describes the occurrence of words within a document. - 1-of-N-coding: Also called ‘one-hot’ coding. Each word in the vocabulary is represented as a vector with a in the position corresponding to the word’s index in the vocabulary and elsewhere. For example, if the corpus contains the words “cat”, “dog”, and “bird”, the one-hot vectors for these words might be , and , respectively.
Word2Vec
Word2Vec is a popular and influential NLP model. There are two main architectures of Word2Vec:
- Skip-Gram: uses a target word to predict context words.
- CBOW (Continuous Bag of Words): This model works the other way around: predicts a target word from a set of context words surrounding it. The context is represented as a bag of words, meaning the order of words does not affect prediction.
The computational complexity of Word2Vec training is with:
- : This represent the dimensionality of the word vectors.
- : the size of the context window.
- : number of unique words of the vocabulary.
Attention Mechanism in Seq2Seq Models
In sequence-to-sequence (Seq2Seq) models with attention, the decoder has an attention mechanism that allows it to focus on different parts of the input sequence while generating the output sequence.
The attention mechanism works by first computing a set of attention weights, which are used to weight the different parts of the input sequence when generating the output. These weights are computed using a function that takes as input the current hidden state of the decoder, , and the hidden states of the encoder, . The attention weights, , are then computed applying the SoftMax function on the scores, as:
where is an attention score computed as:
The idea is to give the decoder more information about the source sequence (the input to the encoder) when generating each target word. The attention mechanism allows the decoder to “pay attention” to different parts of the source sequence at each time step, rather than only considering the final hidden state of the encoder.
The function can be any function that takes two hidden states as input and outputs a scalar attention score. A common choice is to use a dot product or a multi-layer perceptron (MLP) to compute the attention score.
The attention mechanism can be thought of as a way to selectively weight different parts of the input sequence when generating the output, allowing the decoder to focus on the most relevant parts of the input when generating each output time step.
Transformers
Transformers revolutionize sequence processing by focusing on attention. Unlike RNNs, they don’t process one element at a time but look at other tokens to gather context and update token representations.
A Transformer model is made of:
- Scaled Dot-Product Attention: Dynamically focuses on parts of the input with scaling to maintain stability.
- Multi-Head Attention: Runs multiple attention mechanisms in parallel to capture different aspects of the input.
- Position-wise Feed-Forward Networks: Applies neural networks to each position separately for further transformation.
- Embeddings and SoftMax: Converts tokens to vector representations and predicts the next token using a probability distribution.
- Positional Encoding: Adds information about token positions to retain the sequential nature of the input.
This is implemented through:
- Query: current item for which the Transformer is trying to understand the context or find relevant information.
- Key: each key is associated with a particular part of the input and indicates the presence of information relevant to the query.
- Value: actual information that corresponds to each key.
Using Query, Key, and Value facilitates parallel execution and training. Attention is computed as a dot product of the query (a linear transformation of the input) and the keys (a linear transformation of the output):
The Self-Attention mechanism is inherently permutation invariant and does not rely on the position or order of words in a sequence. To make self-attention sensitive to word order, positional encoding is employed.
Positional encoding ensures that the input representation includes both the embeddings for tokens (standard practice) and positions (crucial for Transformers). Although fixed sinusoidal functions were initially used for positional encodings, state-of-the-art Transformers like BERT, RoBERTa, and GPT-2 have evolved to learn positional encodings instead.