Networks
A network is represented by a graph with nodes (or vertices) and links (or edges).
- Undirected Networks: No direction associated with links.
- Directed Networks: Links have a specified direction.
- Weighted Networks: Links have weights representing the strength or capacity of the connection.
Adjacency and Laplacian matrices
Representation of networks using the adjacency matrix is popular. We simply put a in position if exists a link between node and node , otherwise. Typically is a sparse matrix (small density).
A weighted network is described by the weight matrix where if the link exists, otherwise.
The Laplacian matrix is an alternative representation of the network, given by:
It’s symmetric and zero-row-sum.
Bipartite network
Bipartite networks are made up of two different classes of nodes. Each class has a certain number of nodes. Only nodes from different classes can be connected to each other.
For example, in a network of papers and authors, a paper node can only be connected to an author node, and vice versa.
To represent a bipartite network, we can use a rectangular incidence matrix called .
We can also create a projected network by projecting the bipartite network onto one of the classes of nodes, denoted as . In this projected network, the weight of a link between two nodes is determined by the number of common neighbours they have in the original network.
To obtain the weight matrix of the projected network, follow these steps:
- Compute , where is the transpose of matrix . This multiplication will give an intermediate matrix .
- Set the diagonal entries of to zero.
This resulting matrix will correspond to the weight matrix of the projected network.
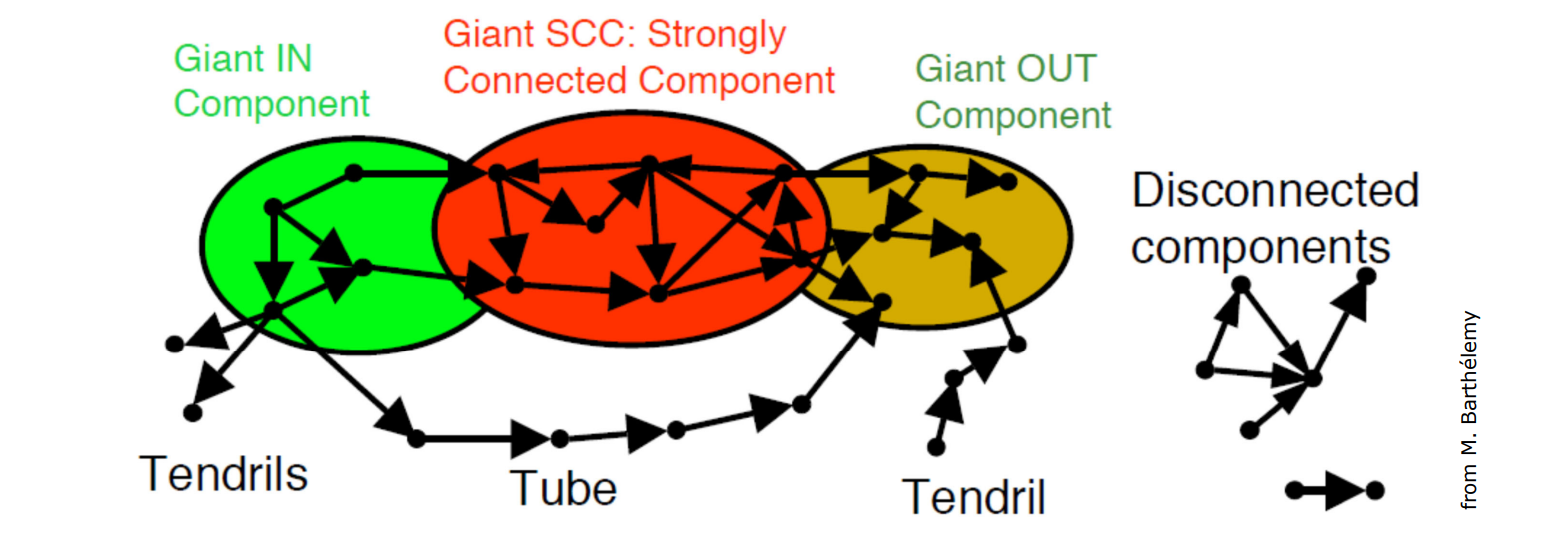
Strongly connected component
It is common to classify components based on their specific properties or the extent of their connectivity. We often refer to highly interconnected sub-sections of a graph as “Strongly Connected Components” or “Giant Out Components” indicating intensive links and relations among its nodes. At the same time, certain components might demonstrate no connectivity or weak connections, forming what we describe as “Disconnected Components”.
Algorithm:
- For each node of the directed graph check if it’s in “communication” with each other node. Where communication means that must have a path to but also must have one to (the graph is directed)
After finding the SCC we can also identify:
- in: set of nodes with links that are pointing to the SCC
- out: set of nodes with links that are reachable from the SCC
- tubes: links that are connecting nodes in the in set with nodes of out set
Basic properties
- For each node of the directed graph check if it’s in “communication” with each other node. Where communication means that must have a path to but also must have one to (the graph is directed)
The Distance is the length (in number of links) of the shortest path connecting two nodes and , denoted as . We can define:
Diameter (D):
The Average Distance (d)
And the Efficiency : with if path does not exist:
“An unconnected pair contributes to the efficiency of the network”
Density
The density of a network:
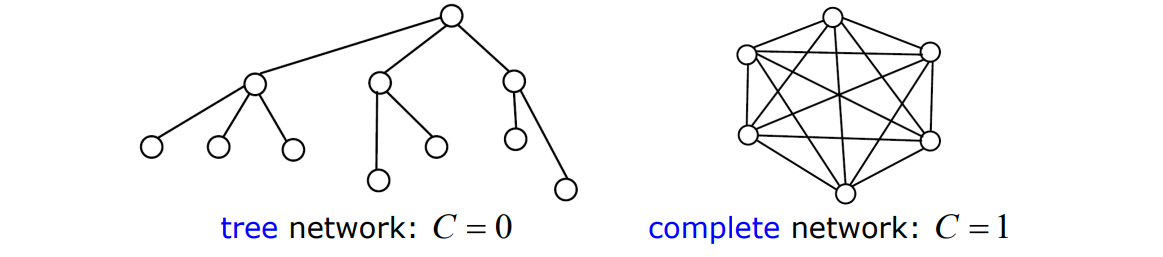
Clustering
Clustering (or Transitivity) Coefficient quantifies “local link density” by counting the triangles in the network. Local Clustering Coefficient of node :
Where is the degree of and the number of links directly connecting neighbors of .
The global clustering coefficient is calculated by averaging individual node coefficients . Global clustering coefficient of a tree is zero (think of the triangles):
Examples:
| Network | Size | Clustering coefficient | Average path length |
|---|---|---|---|
| Internet, domain level [13] | 32711 | 0.24 | 3.56 |
| Internet, router level [13] | 228298 | 0.03 | 9.51 |
| WwW [14] | 153127 | 0.11 | 3.1 |
| E-mail [15] | 56969 | 0.03 | 4.95 |
| Software [16] | 1376 | 0.06 | 6.39 |
| Electronic circuits [17] | 329 | 0.34 | 3.17 |
| Language [18] | 460902 | 0.437 | 2.67 |
| Movie actors [5, 7] | 225226 | 0.79 | 3.65 |
| Math. co-authorship [19] | 70975 | 0.59 | 9.50 |
| Food web [20, 21] | 154 | 0.15 | 3.40 |
| Metabolic system [22] | 778 | - | 3.2 |
Degree Distribution in Networks
Let’s start with the Degree and Strength of a Node:
- Degree in undirected network is the number of links connected to node .
- Strength in a weighted network is the total weight of the links connected to node .
In a directed network we can distinct in,out and total degree/strength.
The **Degree Distribution of a network is the fraction of nodes having exactly degree .
It is often more practical to consider the Cumulative Degree Distribution which is the fraction of nodes with degree :
And the moments of Degree Distribution: are:
The first moment is the average degree which interestingly can be also computed as
Authorities and hubs
Homogeneous Network: All nodes have the same degree. Heterogeneous Network (Real-World): Broad degree distribution, some nodes are highly connected (hubs), while most have few connections.
Said this we can talk about authorities and hubs scores which are based taking into account the different role of in-out links. The formulas of authorities and hubs score are part of a recursive process: the authority score of a node depends on the hub scores of nodes pointing to it, and the hub score of a node depends on the authority scores of the nodes it points to. This interdependency is key in networks where the importance of a node is not just a function of how many connections it has, but also how important those connections are.
Authority Score :
The authority score is calculated by summing the hub scores of all nodes that point to . The adjacency matrix is used to know if there’s a link from node . The factor is a normalization constant to keep the scores from escalating too high.
Hub Score :
The hub score of a node is computed by summing the authority scores of all nodes that node points to. The adjacency matrix indicates whether there is a link from node . The factor serves as a normalization constant to prevent the scores from becoming excessively large.
Nearest neighbors
The degree distribution of nearest neighbours specifies the fraction of nodes’ neighbours having exactly degree (=the probability that a randomly selected neighbour of a randomly selected node has degree ):
It is not but it is biased towards highest degrees:
Thus the average degree of nearest neighbours is:
which is larger than provided (non strictly homogeneous network).
If variance is not equal to zero, is always higher than .
This is the mathematical foundation of the friendship paradox which states that on average, your friends will have more friends than you do. As navigating randomly through a network is more likely to encounter nodes with many connections. This idea has applications for finding hub nodes within a network.
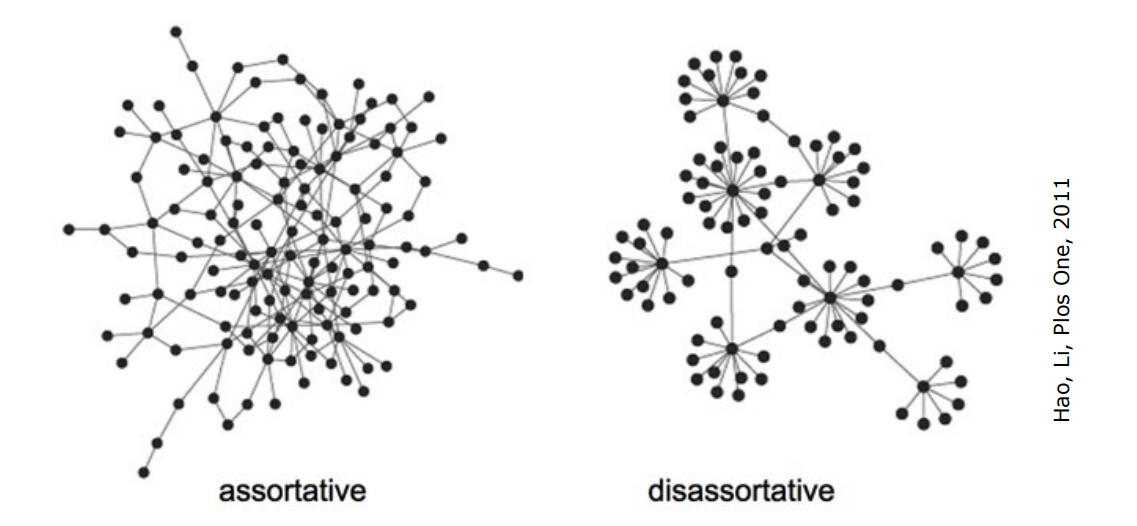
Correlated Networks
There is a correlation between with ? In a degree-correlated network, the probability that the neighbour of a node with degree has degree depends on . Correlations in such a network can be captured by the average nearest neighbour degree function: Practically, this function is computed as: where is the number of nodes with degree . In an assortative network, high-degree nodes tend to connect to other high-degree nodes. Conversely, in a disassortative network, high-degree nodes tend to connect to low-degree nodes.
In an assortative network, high-degree nodes tend to connect to other high-degree nodes. Conversely, in a disassortative network, high-degree nodes tend to connect to low-degree nodes.
In summary, provides insight into the degree correlation patterns within a network, revealing how nodes of a certain degree tend to connect with other nodes of specific degrees.
Random walks on networks
A random walk is a path formed by a sequence of random steps. Random walks have many variants:
- Discrete vs continuous time
- Uniform vs non-uniform steps
- Markovian vs non-Markovian processes
- etc.
Random walks have practically unlimited applications across all scientific fields: ecology, economics, psychology, computer science, physics, chemistry, and biology.
In a unweighted network, the random walker at node chooses an out-link with uniform probability:
In a weighted network, the out-link is chosen with probability proportional to its weight:
The transition matrix is the matrix which represents the probabilities of a random walker moving from node to any node . The probabilities are not symmetric because each row is normalized with .
state probability probability of being in node at time . evolves according to the Markov chain equation:
If the network is strongly connected, then:
- The transition matrix is irreducible.
- There exists a unique stationary state probability distribution , which is strictly positive for all .
Observations:
- In undirected networks, is the (rescaled) node strength: .
- In directed networks, is mostly correlated to the in-strength (e.g., WWW).
Google PageRank
The solution to might not be unique, positive, or the Markov chain might not even be well-defined. PageRank uses teleportation: at each time step, the random walker has a probability to jump to a randomly selected node.
A suitable value for is not too large (to avoid heavily modifying the network) nor too small (to prevent from being too sensitive to ). The standard (Google) value is .
PageRank’s revolution is that the rank emerges naturally from the self-organized internet structure. A high rank is achieved only if many other nodes point to it, creating a naturally emerged rank.
Node centrality
The centrality of a node is a measure of its importance in the network. The importance of a node can trivially be captured by the number of its neighbours (or in a weighted networks by the strength ). Considering central a node which has an high number of connections is a simple measure but we can also consider other criteria.
Betweenness centrality
Betweenness Centrality of node is calculated as the number of all shortest paths in the network that pass through .
Betweenness can be a valid and very useful property to consider in the computation of centrality in some models/networks.
Closeness centrality
A node is considered central if it is, on average, close to all the other nodes in a network. This means it has better access to information, more direct influence on other nodes, and so on. To calculate this average distance, we can use the formula:
The closeness centrality is defined as
If the network is directed, we need to differentiate between in-closeness and out-closeness. If the network is weighted, there are several alternative definitions available for closeness centrality.
Eigenvector centrality
” I’m important if I’m friend of important people ”
It’s just called eigenvector because it’s computed using eigenvectors of the adjacency matrix. The centrality is (proportional to) the sum of the centralities of the neighbours (i.e., a node is important if it relates to important nodes).
Letting and , we obtain the eigenvector equation:
If the network is connected ( is irreducible), the centralities are given by the only solution with for all (Frobenius-Perron theorem).
- “Quantitative Sociologists” (who is the most influential individual?)
- applications in web searching (with some modifications: Google “PageRank” which is the most important webpage?)
- another modification is Katz (or alpha-) centrality: just a variant to solve some degeneration problem of the eigenvector centrality in not completely connected networks.
Random walker centrality
is the state probability, which means the probability of being in node at time :
With we can define the centrality of node represents fraction of time spent on node by a random walker (only if the network is strongly connected). Basically this quantity/metric/centrality represents the frequency to find the random walker at node .
“A node is important if is visited many times”
Random walker centrality is useless in undirected and unweighted networks since it is the rescaled node degree:
In undirected but weighted networks:
In directed networks, turns out to be mostly correlated to the in-strength :