Distributed agreement in practice
Distributed commit
We will discuss the concept of Distributed Commit, specifically focusing on atomic commitment. In a DS, the challenge arises when we want to commit operations to databases that are partitioned.
Atomic commit refers to a transaction which refers to the atomicity ACID property: the transaction is either completely successful or completely unsuccessful, no intermediate state is possible.
| Consensus | Atomic commit |
|---|---|
| One or more nodes propose a value | Every node votes to commit or abort |
| Nodes agree on one of the proposed value | Commit if and only if all nodes vote to commit, abort otherwise |
| Tolerates failures, as long as a majority of nodes is available | Any crash leads to an abort |
- Termination:
- If there are no faults, all processes eventually decide (weak)
- All non-faulty processes eventually decide (strong)
There are two different commit protocols:
- Two-phase commit (2PC): sacrifices liveness (blocking protocol)
- Three-phase commit(3PC): more robust, but more expensive so not widely used in practice
General result (FLP theorem): you cannot have both liveness and safety in presence of network partitions in an asynchronous system.
2PC
2PC is a blocking protocol which satisfies the weak termination condition, allowing to reach an agreement in less than rounds.
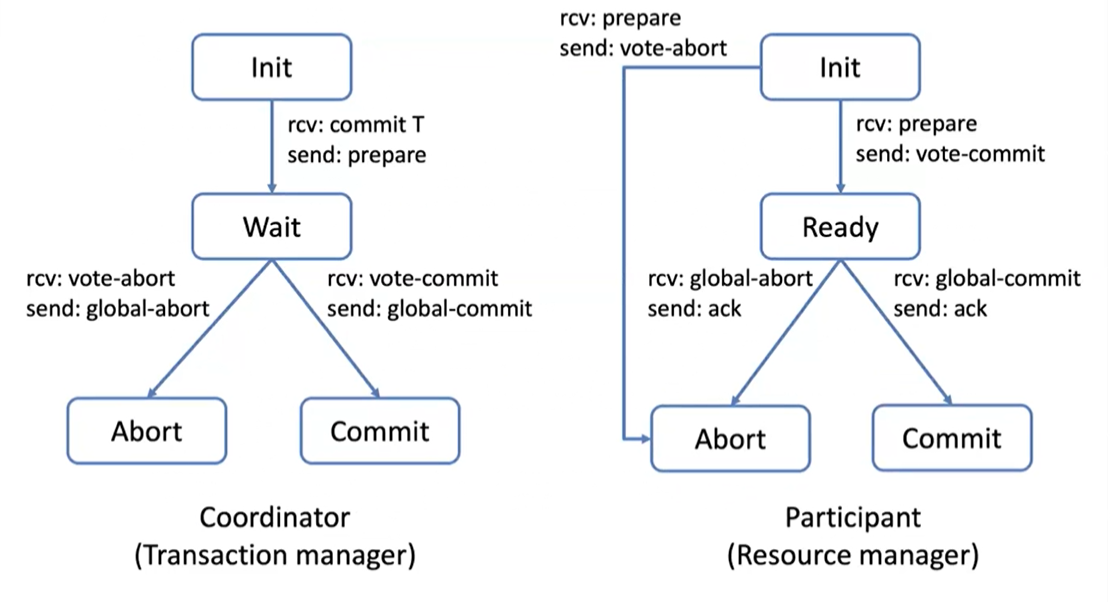
2PC failure scenarios
1. Participant Failure:
- Before Voting:
- If a participant fails before casting its vote, the coordinator can assume an abort message after a timeout
- After Voting (Before Decision):
- If a participant fails after voting to commit, the coordinator cannot proceed to a global commit without confirmation from all participants.
2. Coordinator Failure:
- Before Vote Request:
- Participants waiting for a vote request (in
INITstate) can safely abort if the coordinator fails.
- Participants waiting for a vote request (in
- After Vote Request (Before Decision):
- Participants in the
READYstate, having voted but awaiting a global decision, cannot unilaterally decide. They must wait for the coordinator’s recovery or seek the decision from other participants.
- Participants in the
3. Consensus Inability:
- Coordinator fail before decision make an indeterminate State:
- If the coordinator fails before sending a commit or abort message and any participant is in the
READYstate, that participant cannot safely exit the protocol. - Nothing can be decided until the coordinator recovers!
- 2PC is vulnerable to a single-node failure (the coordinator)
- Participants in the
READYstate are left in limbo, unable to commit or abort, demonstrating the inability of 2PC to reach consensus in the event of certain failures.
- If the coordinator fails before sending a commit or abort message and any participant is in the
3PC
3PC is designed to overcome the blocking nature of 2PC by introducing an additional phase, which allows the protocol to avoid uncertainty even in the case of a coordinator failure.
- Phase 1 (prepare):
- The coordinator asks participants if they can commit. Participants respond with their agreement or disagreement.
- Phase 2 (prepare commit):
- If all participants agree, the coordinator sends a pre-commit message. Participants then prepare to commit but do not commit yet.
- Phase 3 (global commit):
- Finally, the coordinator sends a global-commit message to finalize the transaction.
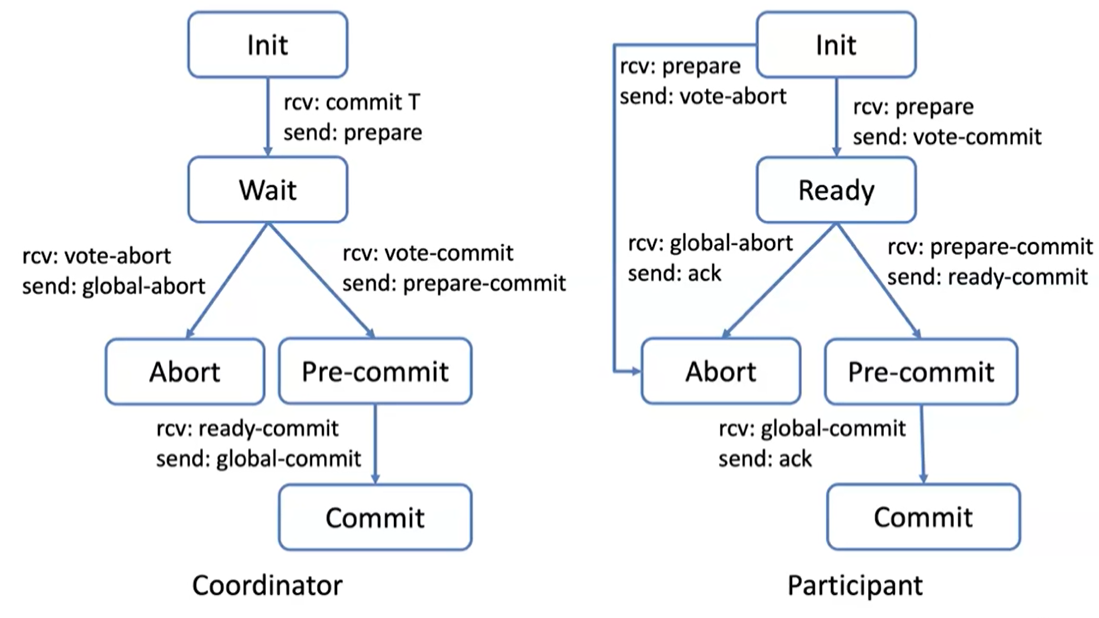
3PC reduces the risk of blocking by ensuring that participants can make a safe decision even if the coordinator fails, provided they have reached the pre-commit phase. 3PC is a non-blocking protocol, which satisfies the strong termination condition but may require a large number of rounds to terminate. The good thing is that with no failures, only 3 rounds are required. Also timeouts are crucial in 3PC to ensure progress in the presence of failures. Participants will proceed to the next phase or abort based on timeouts.
3PC failure scenarios
- Coordinator Failure:
- If the coordinator fails before sending the pre-commit message, participants who have not received this message can safely abort.
- If the coordinator fails after sending the pre-commit message but before the do-commit message, participants enter the ‘uncertain’ phase but will decide to commit once a timeout occurs, as they know that all participants were ready to commit.
- Participant Failure:
- Participant failures are handled similarly to 2PC, but with the additional pre-commit phase providing a buffer that can prevent the system from entering a blocked state.
Termination Protocols in 3PC:
- Coordinator Termination:
- If the coordinator recovers from a failure, it performs a termination protocol to determine the state of the participants and decide on the next step.
- Participant Termination:
- Participants also have a termination protocol to follow if they recover from a failure, which involves communicating with other participants to determine the global state.
CAP theory
Any distributed system where nodes share some (replicated) shared data can have at most two of these three desirable properties
- C: consistency equivalent to have a single up-to-date copy of the data
- A: high availability of the data for updates (liveness)
- P: tolerance to network partitions
In presence of network partitions, one cannot have perfect availability and consistency.
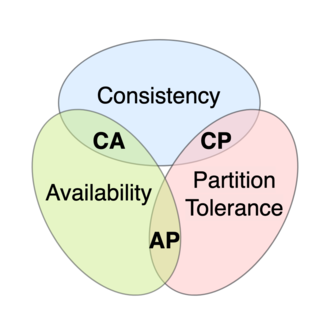 {width=50%}
{width=50%}
For the hodlers out there we can say that the blockchain trilemma is a concept that was derived from CAP Theorem.
Replicated state machine
A general purpose consensus algorithm enables multiple machines to function as a unified group. These machines work on the same state and provide a continuous service, even if some of them fail. From the viewpoint of clients, this group of machines appears as a single fault-tolerant machine.
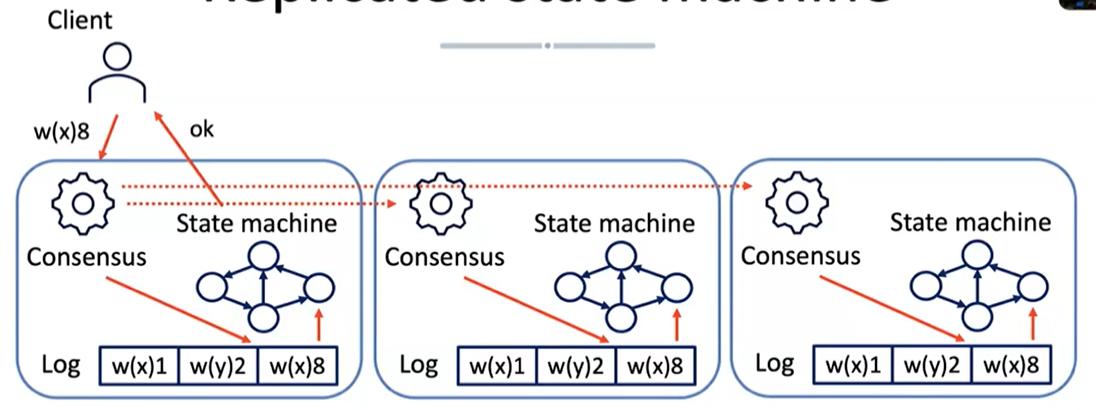
The idea is that the client connects to a leader which writes the operations onto a log. This log contains a sequence of operations that need to be propagated to the other nodes in the system through a consensus protocol. The ultimate objective is to maintain a coherent view of the system regardless of failures and network issues.
Paxos
Paxos, proposed in 1989 and published in 1998, has been the reference algorithm for consensus for about 30 years. However, it has a few problems.
- allows agreement on a single decision, not on a sequence of requests. This issue is solved by multi-Paxos.
- Paxos is difficult to understand, making it challenging to use in practice.
- No reference implementation of Paxos: here is often a lack of agreement on the details of its implementation.
Raft
Raft is a consensus algorithm designed for managing a replicated log. It’s used to ensure that multiple servers agree on shared state even in the face of failures.
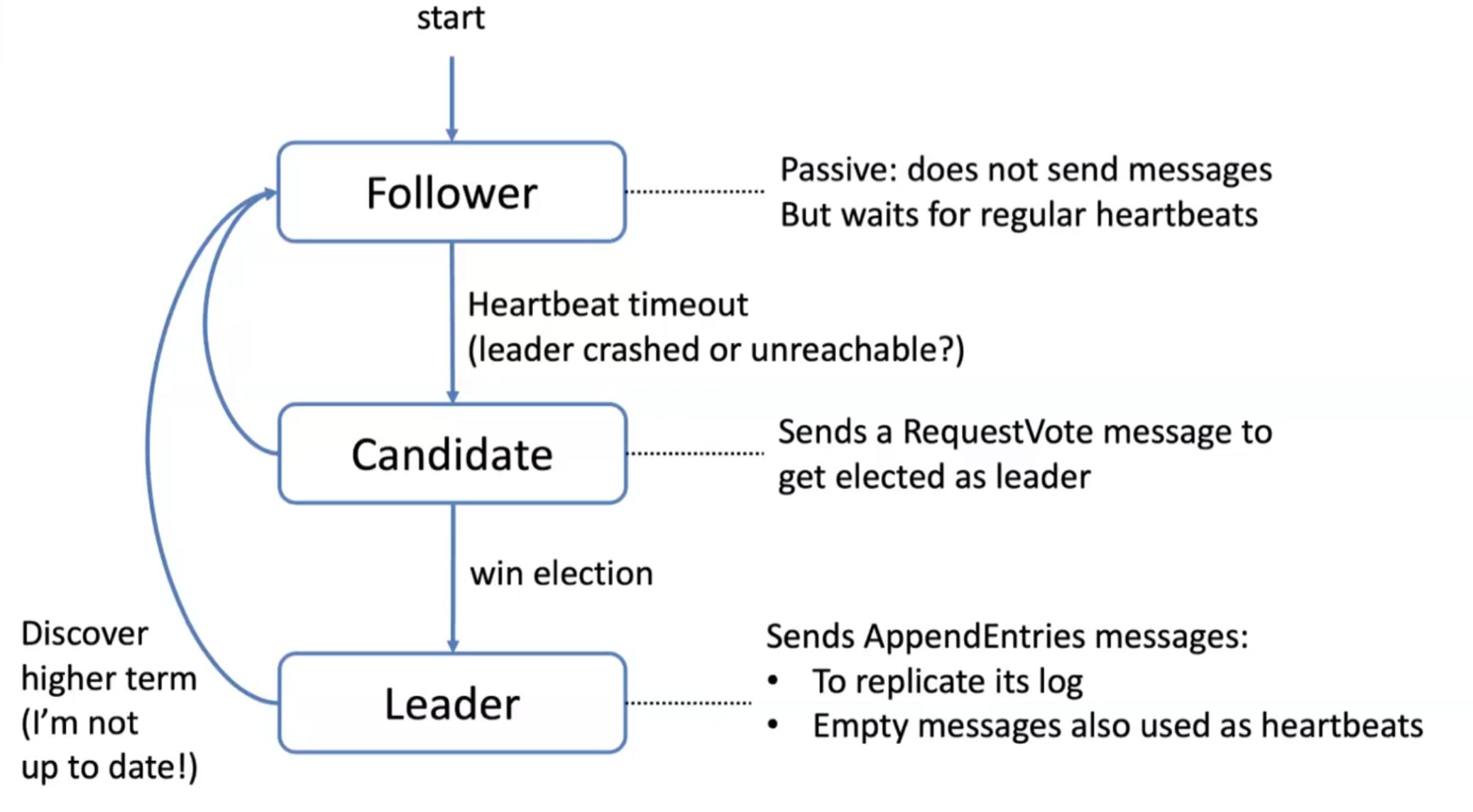
- Server States:
- Servers can be in one of three states: leader, follower, or candidate.
- The leader handles all client interactions and log them
- The log is then replicated and passive followers respond to the leader’s requests.
- Candidates are used to elect a new leader if the current leader fails.
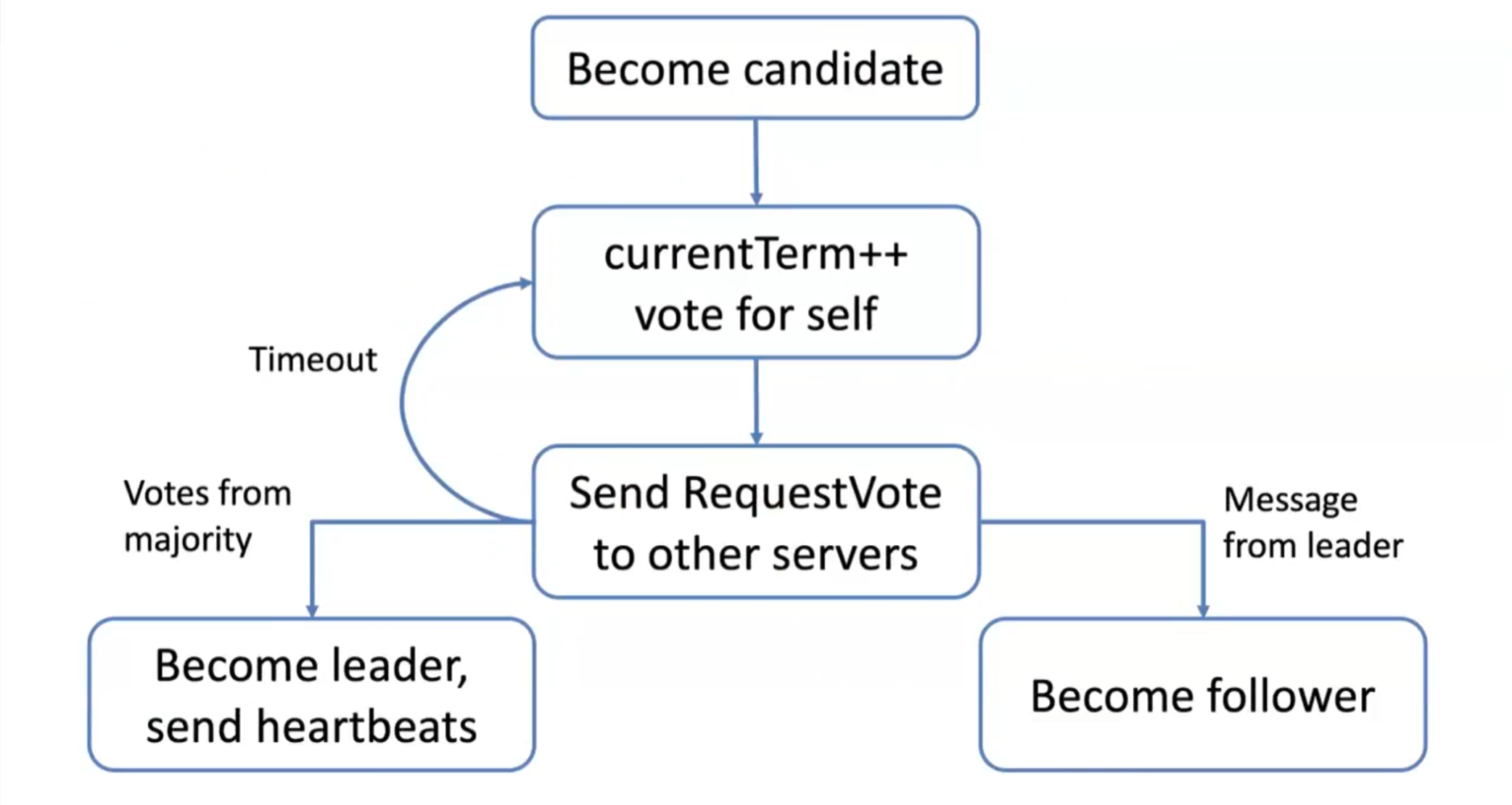
- Leader Election:
- In the event of a leader crash, a leader election process is initiated
- Raft uses randomized timeouts to prevent multiple parallel elections from occurring simultaneously
- If a follower receives no communication from the leader within a certain timeframe, it becomes a candidate and starts a new election.
- Log Replication:
- Followers append entries to their logs only if they match the leader’s log up to the newest entry.
Log matching consistency
Log matching consistency is a property that guarantees the consistency of log entries across different servers. To achieve this Raft divides time into terms of arbitrary length:
- Terms are numbered with consecutive integers
- Each server maintains a current term value
- Exchanged in every communication
- Terms identify obsolete information
This property ensures that if log entries on different servers have the same <index,term>, they will store the same command.
Furthermore Raft implements leader completeness: once a log entry is committed, all future leaders must store that entry. Servers with incomplete logs cannot be elected as leaders. Meanwhile, in terms of communication with clients, it’s guaranteed that clients always interact with the leader: this because when a client starts, it connects to a random server, which communicates the leader for the current term to the client.
Blockchains
Blockchains can be seen as replicated state machines, where the state is stored in the replicated ledger, which acts as a log and keeps records of all operations or transactions. Also blockchains can be modeled inside a “byzantine environment”: misbehaving user (byzantine failures) attempting to double spend (or actions inconsistent with the state) their money by creating inconsistent copies of the log. Overall, the choice of approach depends on the trade-offs between search expressivity, performance, and network fragility.