Stencil
A stencil in computational terms refers to a pattern of computing values on a grid where each point’s value is determined based on the values of its neighboring points. This is similar to the process of convolution, often used in image processing, where a matrix (kernel) is slid over data to compute outputs based on the kernel’s weighted sum of the input values it covers.
void stencil_cpu(const float *in, float *out, const int N) {
for (int i = 1; i < N - 1; ++i)
for (int j = 1; j < N - 1; ++j)
for (int k = 1; k < N - 1; ++k)
get(out, i, j, k, N) =
c0 * get(in, i, j, k, N)
+ c1 * get(in, i, j, k - 1, N) +
c2 * get(in, i, j, k + 1, N)
+ c3 * get(in, i, j - 1, k, N)
+ c4 * get(in, i, j + 1, k, N)
+ c5 * get(in, i - 1, j, k, N) +
c6 * get(in, i + 1, j, k, N);
}Stencil computations are crucial in fields like computational fluid dynamics, heat conductance, weather forecasting, and electromagnetics. Stencils are often used to approximate derivative values from discrete data points that represents physical quantities.
- Naive Implementation: Assign one GPU thread per grid point. Each thread calculates the output for a point without needing to wait for other threads, making the process highly parallel.
// Kernel function for GPU
__global__ void stencil_kernel_gpu(const float *__restrict__ in, float *__restrict__ out, const int N) {
const unsigned int i = blockIdx.z * blockDim.z + threadIdx.z;
const unsigned int j = blockIdx.y * blockDim.y + threadIdx.y;
const unsigned int k = blockIdx.x * blockDim.x + threadIdx.x;
if (i >= 1 && i < N - 1 && j >= 1 && j < N - 1 && k >= 1 && k < N - 1) {
get(out, i, j, k, N) =
c0 * get(in, i, j, k, N)
+ c1 * get(in, i, j, k - 1, N)
c2 * get(in, i, j, k + 1, N)
+ c3 * get(in, i, j - 1, k, N)
+ c4 * get(in, i, j + 1, k, N)
+ c5 * get(in, i - 1, j, k, N) +
c6 * get(in, i + 1, j, k, N);
}
}Several strategies can improve performance and efficiency:
- Tiling and Privatization: Use shared memory on the GPU to reduce the frequency of data transfer between the GPU and its main memory.
- Coarsening and Slicing: Adjust the organization of threads and data to better fit the GPU’s architecture, enhancing performance without exceeding memory capacities.
- Register Tiling: Use GPU registers to store data temporarily, reducing the reliance on shared memory and thus saving space.
Tiling and Privatization
Differences:
- each thread still corresponds to a cell in the grid, much like in the naive version
- Before performing computations, this kernel loads necessary data into a shared memory array (
in_s)
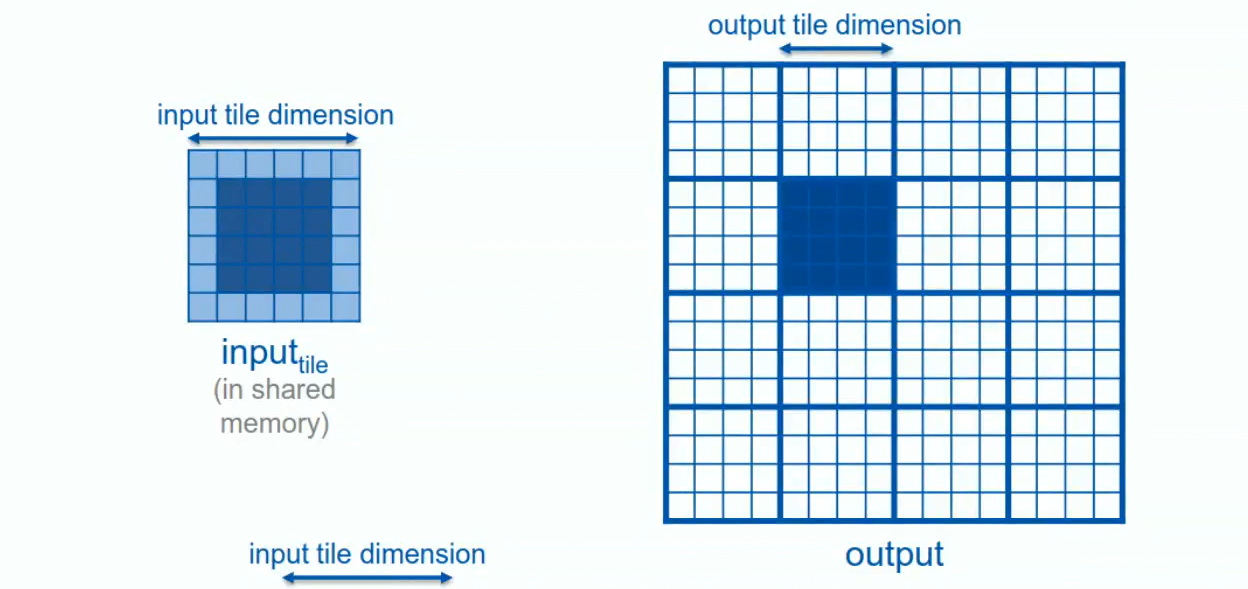
// Tiling and Privatization
__global__ void stencil_kernel_tiling_gpu(const float *__restrict__ in, float *__restrict__ out, const int N) {
const unsigned int i = blockIdx.z * OUT_TILE_DIM + threadIdx.z - 1;
const unsigned int j = blockIdx.y * OUT_TILE_DIM + threadIdx.y - 1;
const unsigned int k = blockIdx.x * OUT_TILE_DIM + threadIdx.x - 1;
__shared__ float in_s[IN_TILE_DIM][IN_TILE_DIM][IN_TILE_DIM];
// Greater than 0 not required since unsigned int are used
if (i < N && j < N && k < N) {
in_s[threadIdx.z][threadIdx.y][threadIdx.x] = get(in, i, j, k, N);
}
__syncthreads();
if (i >= 1 && i < N - 1 && j >= 1 && j < N - 1 && k >= 1 && k < N - 1) {
if (threadIdx.z >= 1 && threadIdx.z < IN_TILE_DIM - 1 && threadIdx.y >= 1 &&
threadIdx.y < IN_TILE_DIM - 1 && threadIdx.x >= 1 && threadIdx.x < IN_TILE_DIM - 1) {
get(out, i, j, k, N) = c0 * in_s[threadIdx.z][threadIdx.y][threadIdx.x] +
c1 * in_s[threadIdx.z][threadIdx.y][threadIdx.x - 1] +
c2 * in_s[threadIdx.z][threadIdx.y][threadIdx.x + 1] +
c3 * in_s[threadIdx.z][threadIdx.y - 1][threadIdx.x] +
c4 * in_s[threadIdx.z][threadIdx.y + 1][threadIdx.x] +
c5 * in_s[threadIdx.z - 1][threadIdx.y][threadIdx.x] +
c6 * in_s[threadIdx.z + 1][threadIdx.y][threadIdx.x];
}
}
}Coarsening and Slicing
This optimization strategy addresses the limitations posed by block sizes in GPU computations. By dividing the computation into slices and iterating over them, we enhance the use of the GPU’s memory and processing capabilities.
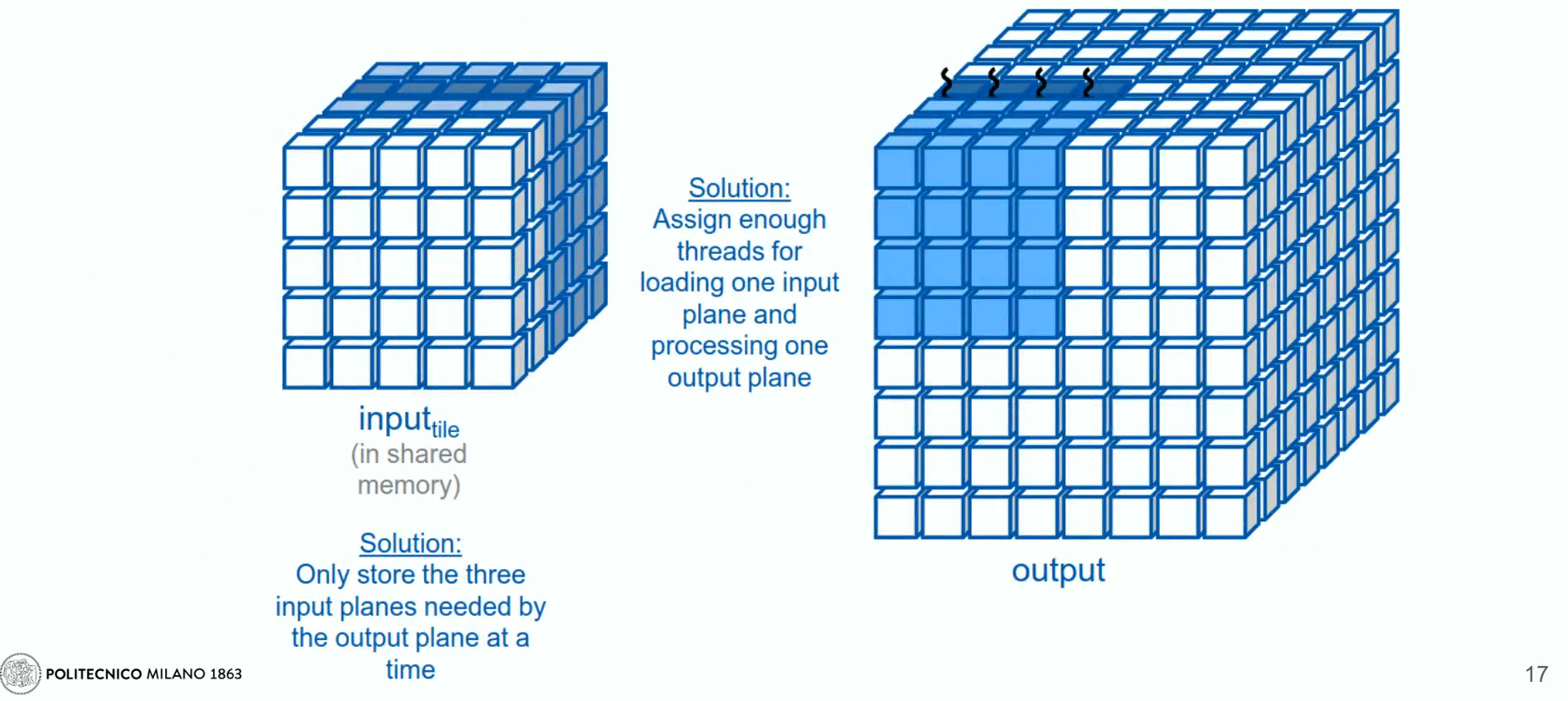
- Thread Coarsening: Instead of processing the entire 3D matrix at once, each thread block handles one slice of the x-y plane at a time. This iteration happens in the z-direction.
- Memory Management: Only three slices of the input matrix are stored at any time: the previous, current, and next. This reduces memory requirements significantly.
- Initial Setup: 3 slices along the z-axis: the current, the previous and next slices into shared memory before starting the computation loop. After computation, update the shared memory to prepare for the next slice.
- Efficiency: This method minimizes the amount of shared memory needed and increases the arithmetic intensity, which is closer to the optimal value of 3.25 operations per byte (OP/B).
- Memory Switching: Similar to a buffer system, shared memory layers are rotated to continuously reuse and update data without frequent global memory access.
__global__ void
stencil_kernel_coarsening_tiling_gpu(const float *__restrict__ in, float *__restrict__ out, const int N) {
const unsigned int i_start = blockIdx.z * Z_SLICING;
const unsigned int j = blockIdx.y * OUT_TILE_DIM + threadIdx.y - 1;
const unsigned int k = blockIdx.x * OUT_TILE_DIM + threadIdx.x - 1;
__shared__ float in_prev_s[IN_TILE_DIM][IN_TILE_DIM];
__shared__ float in_curr_s[IN_TILE_DIM][IN_TILE_DIM];
__shared__ float in_next_s[IN_TILE_DIM][IN_TILE_DIM];
// Check greater than 0 not needed since index is an unsigned int
if (i_start - 1 < N && j < N && k < N) {
in_prev_s[threadIdx.y][threadIdx.x] = get(in, i_start - 1, j, k, N);
}
if (i_start < N && j < N && k < N) {
in_curr_s[threadIdx.y][threadIdx.x] = get(in, i_start, j, k, N);
}
for (unsigned int i = i_start; i < i_start + Z_SLICING; ++i) {
// Check greater than 0 not needed since index is an unsigned int
if (i + 1 < N && j < N && k < N) {
in_next_s[threadIdx.y][threadIdx.x] = get(in, i + 1, j, k, N);
}
__syncthreads();
if (i >= 1 && i < N - 1 && j >= 1 && j < N - 1 && k >= 1 && k < N - 1) {
if (threadIdx.y >= 1 && threadIdx.y < IN_TILE_DIM - 1 && threadIdx.x >= 1 &&
threadIdx.x < IN_TILE_DIM - 1) {
get(out, i, j, k, N) =
c0 * in_curr_s[threadIdx.y][threadIdx.x]
+ c1 * in_curr_s[threadIdx.y][threadIdx.x - 1]
+ c2 * in_curr_s[threadIdx.y][threadIdx.x + 1]
+ c3 * in_curr_s[threadIdx.y - 1][threadIdx.x]
+ c4 * in_curr_s[threadIdx.y + 1][threadIdx.x]
+ c5 * in_prev_s[threadIdx.y][threadIdx.x]
+ c6 * in_next_s[threadIdx.y][threadIdx.x];
}
}
__syncthreads();
in_prev_s[threadIdx.y][threadIdx.x] = in_curr_s[threadIdx.y][threadIdx.x];
in_curr_s[threadIdx.y][threadIdx.x] = in_next_s[threadIdx.y][threadIdx.x];
}
}Registers optimization
Reducing the use of shared and register memory: only store a single slice of the data grid at any iteration. By allocating the next slice’s data elements to registers and only transferring them to shared memory when they become the current slice, then moving them back to registers once they become the previous slice.
__global__ void
stencil_kernel_register_tiling_gpu(const float *__restrict__ in, float *__restrict__ out, const int N) {
const unsigned int i_start = blockIdx.z * Z_SLICING;
const unsigned int j = blockIdx.y * OUT_TILE_DIM + threadIdx.y - 1;
const unsigned int k = blockIdx.x * OUT_TILE_DIM + threadIdx.x - 1;
float in_prev;
__shared__ float in_curr_s[IN_TILE_DIM][IN_TILE_DIM];
float in_next;
// Check greater than not needed since index is an unsigned int
if (i_start - 1 < N && j < N && k < N) {
in_prev = get(in, i_start - 1, j, k, N);
}
if (i_start < N && j < N && k < N) {
in_curr_s[threadIdx.y][threadIdx.x] = get(in, i_start, j, k, N);
}
for (unsigned int i = i_start; i < i_start + Z_SLICING; ++i) {
// Check greater than not needed since index is an unsigned int
if (i + 1 < N && j < N && k < N) {
in_next = get(in, i + 1, j, k, N);
}
__syncthreads();
if (i >= 1 && i < N - 1 && j >= 1 && j < N - 1 && k >= 1 && k < N - 1) {
if (threadIdx.y >= 1 && threadIdx.y < IN_TILE_DIM - 1 && threadIdx.x >= 1 &&
threadIdx.x < IN_TILE_DIM - 1) {
get(out, i, j, k, N) =
c0 * in_curr_s[threadIdx.y][threadIdx.x]
+ c1 * in_curr_s[threadIdx.y][threadIdx.x - 1]
+ c2 * in_curr_s[threadIdx.y][threadIdx.x + 1]
+ c3 * in_curr_s[threadIdx.y - 1][threadIdx.x]
+ c4 * in_curr_s[threadIdx.y + 1][threadIdx.x]
+ c5 * in_prev + c6 * in_next;
}
}
__syncthreads();
in_prev = in_curr_s[threadIdx.y][threadIdx.x];
in_curr_s[threadIdx.y][threadIdx.x] = in_next;
}
}- Single Slice in Shared Memory: Only the current slice is maintained in shared memory, reducing the shared memory requirements significantly.
- Register Usage: Two additional registers per thread are used to store the previous and next slices’ data, enabling quick access and modifications without repeatedly accessing shared memory.
- Memory Switching: The stencil computations involve rotating the data between registers and shared memory, reducing the frequency and cost of memory accesses.
Smaller shared memory usage → scarse resources is not registers but shared memory