Model validation
Given an optimal model the goal is to validate its optimality also considering its model order Using measured samples, one can estimate the prediction error variance through , which evaluates the performance of the predictive model:
At the end we can say that even with measured samples (so finite data) asymptotically we will converge to the minimum of the asymptotic cost since: which implies that:
PEM converges to real
Now let’s prove that when the model set incorporates the actual dynamics of the system, the identified model using the prediction error method converges to the precise representation of the real system.
More formally, let’s prove that if PEM guarantees that or alternatively let’s prove that .
Last passage is possible since in the case of the global optimum (as said above, PEM is guarantee to converge to the minimum of the asymptotic cost so ).
This theorem is very, very significant: if the system that you want to model and learn from data is inside the model set, you will converge asymptotically (so with a large data set) to exactly that system.
It means that the prediction error algorithm that we are using in this course is actually good, meaning that they will lead you to the right model (at least in this very ideal case where the system is in the model set).
Actually it’s very rare that .
Let’s summary the possible cases:
- and is a singleton : for will converge to . The identification problem is properly defined, ensuring a singular, accurate solution that aligns with the system’s dynamics.
- and is not a singleton : for will not necessary converge to , but it’s guarantee tends to one of the values in (multiple optimal minima subset). Multiple models equally represent the system.
- and is a singleton: for will converge to . In this case the model with is the best proxy of the true system in the selected family. There is an insufficiency of the model set to capture the system’s complexity.
- and is not a singleton: for no guarantees. In this case the model with tends to one of the best proxies of the true system in the selected family. The model is too complex for the model or the data are not representative enough, basically we don’t know how to choose in a set of equivalent models.

Model order selection
How can we select the best value of namely the best model complexity? Remember that in function of is always non increasing but it’s not the optimal predictor!
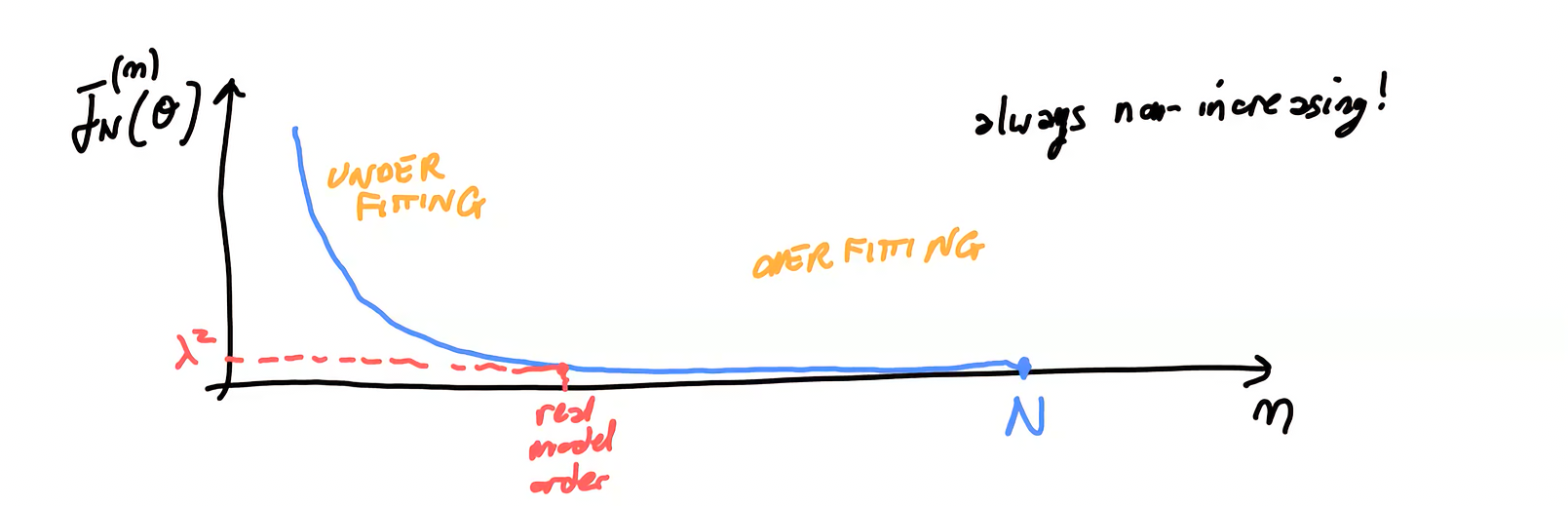
So in general an is a better fit to the data than an model, but we can’t simply continue to use more parameters, we would overfit it.
Whiteness test on residuals
If we simply compute the performance index for multiple increasing values of we will see that is monotonically decreasing with : we can use the whiteness test on residuals to understand when “it’s enough” and that further decreasing will not reflect in better performance for new unseen data (overfit).
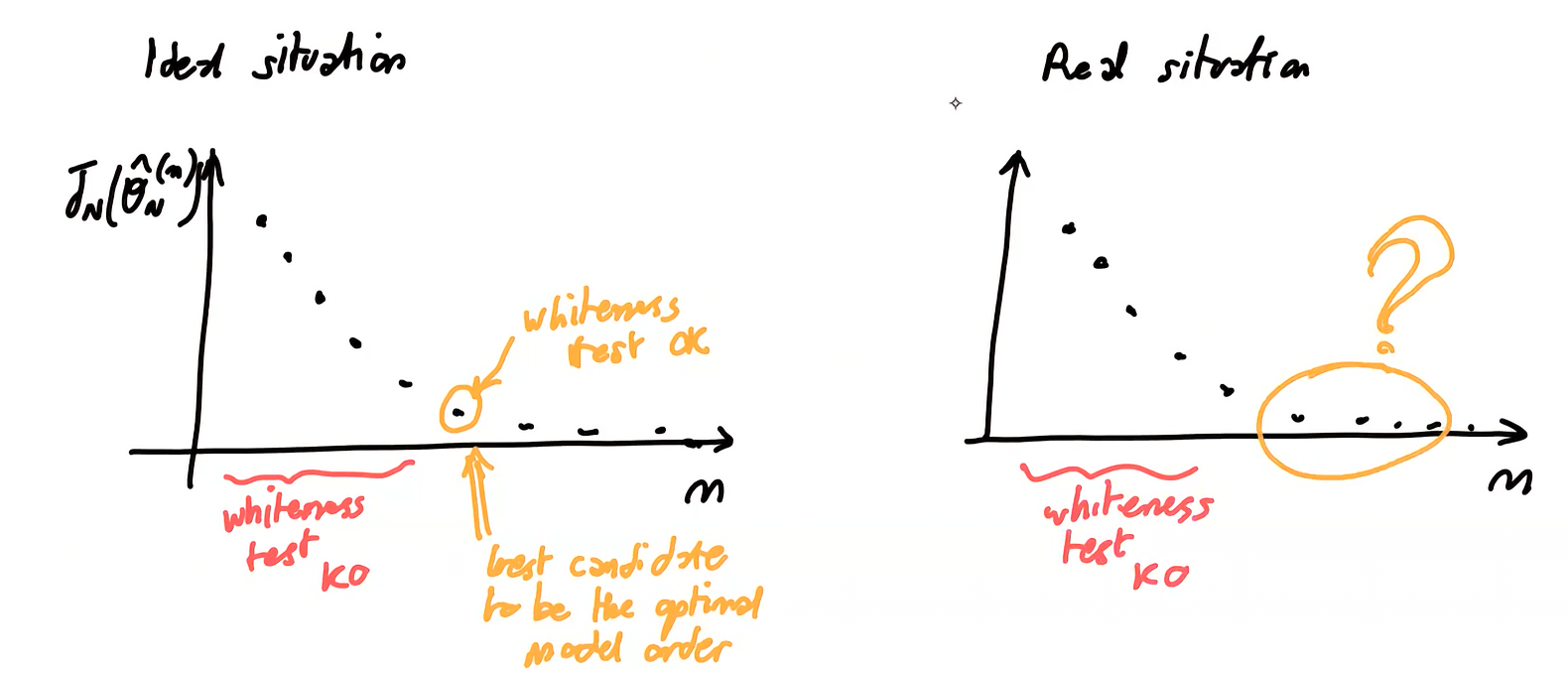
Actually this method is not robust and it’s not used.
Cross-validation
In cross-validation, the dataset is partitioned into an identification set (or training), which is used to construct the model, and a validation set, which is utilized to assess the model’s performance. The validation portion of the data is “reserved” and not used in the model-building phase, potentially leading to data “wastage”.
Identification with model order penalties
For better model selection that help prevent over-fitting we can directly control model complexity.
FPE (Final Prediction Error)
Identification with model order penalties:
We are giving a penalty to the models with high complexity. The FPE functions is not monotonically decreasing, and the complexity corresponding to its minimum value can be chosen as complexity of the model.
AIC (Akaike Information Criteria)
For high values of , this is equivalent to .
MDL (Minimum Description Length)
Asymptotically is similar to AIC but with higher penalization since . In general case we usually prefer to (slightly) overfit, so generally AIC is preferred.